
一、软件生命周期
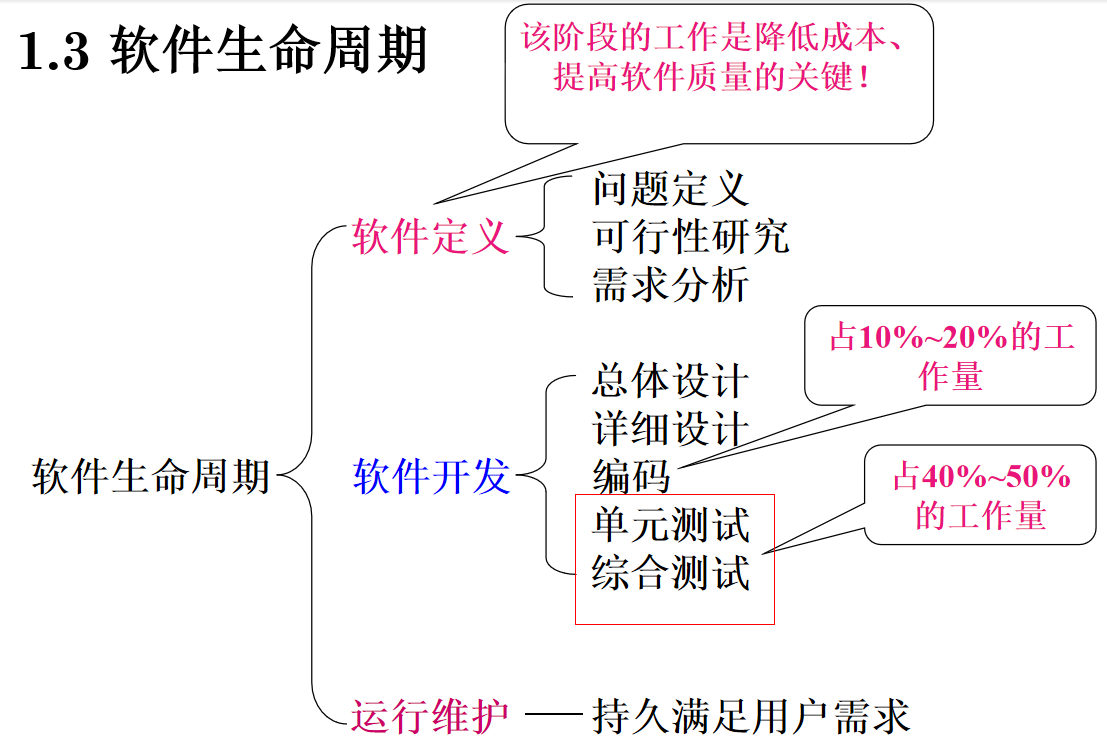
每阶段的基本任务:
- 问题定义-- 要解决的问题是什么?
- 可行性研究-- 对于上一个阶段所确定的问题有行得通的解决办法吗?
- 需求分析-- 确定目标系统必须做什么,记录需求。
- 总体设计-- 提出几种实现方案(低成本、中成本、高成本),选择最佳方案并制定详细计划。
- 详细设计-- 具体设计实现细节,包括算法和数据结构。
- 编码和单元测试--编写程序模块并进行单元测试,确保代码正确、可读、易维护。
- 综合测试--通过各种类型的测试(及相应的调试)使软件达到预定的要求。
- 软件维护--通过各种必要的维护活动使系统持久地满足用户的需要。
二、数据流图DFD
DFD ------Data Flow Diagram
- 定义与本质:一种图形化技术,用于描述信息与数据从输入到输出过程中的变换过程。
- 逻辑性:仅描述数据流动与处理的逻辑过程,不涉及任何物理实现细节,是系统逻辑功能的图形化表示。
- 设计视角:关注系统“必须完成的基本逻辑功能”,不考虑“如何具体实现”。
- 作用:是后续软件设计的良好起点
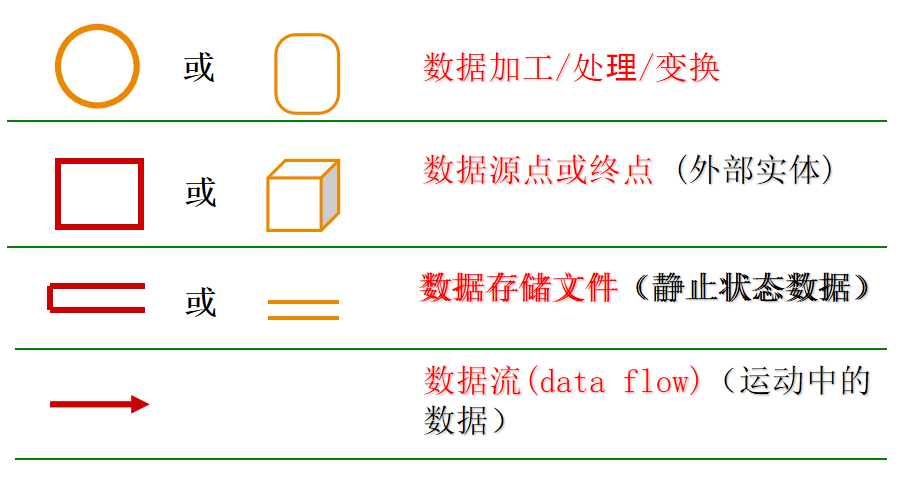
2.1、数据流图四种基本符号
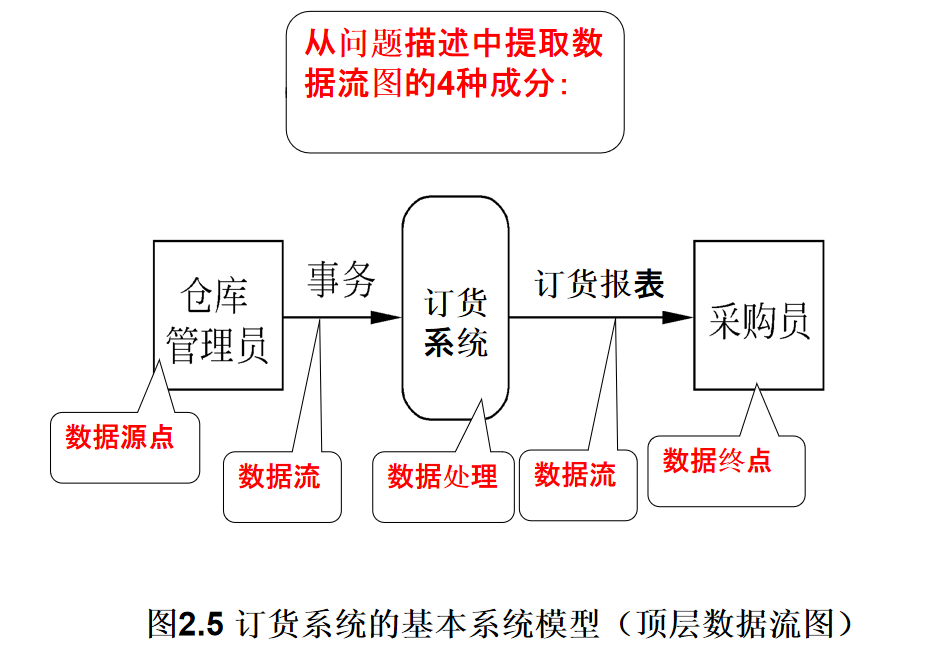
2.2、最小的简单数据流图示例

注意:
绘制DFD应采用分层结构,通过自顶向下、逐层分解的方式,将系统分解为多个层次的细节。这种层次化的表达方法能清晰展示系统结构,便于理解。
- 规模控制:单张图的处理不宜超过9个,过多时应拆分画图。
- 信息连续:分解前后,对应的输入输出数据流必须完全相同。
2.3、举例
假设一家工厂的采购部每天需要一张订货报表,报表按零件编号排序,表中列出所有需要再次订货的零件。对于每个需要再次订货的零件应该列出下述数据:零件编号,零件名称,订货数量,目前价格,主要供应者,次要供应者。零件入库或出库称为事务,通过放在仓库中的CRT终端把事务报告给订货系统。当某种零件的库存数量少于库存量临界值时就应该再次订货。
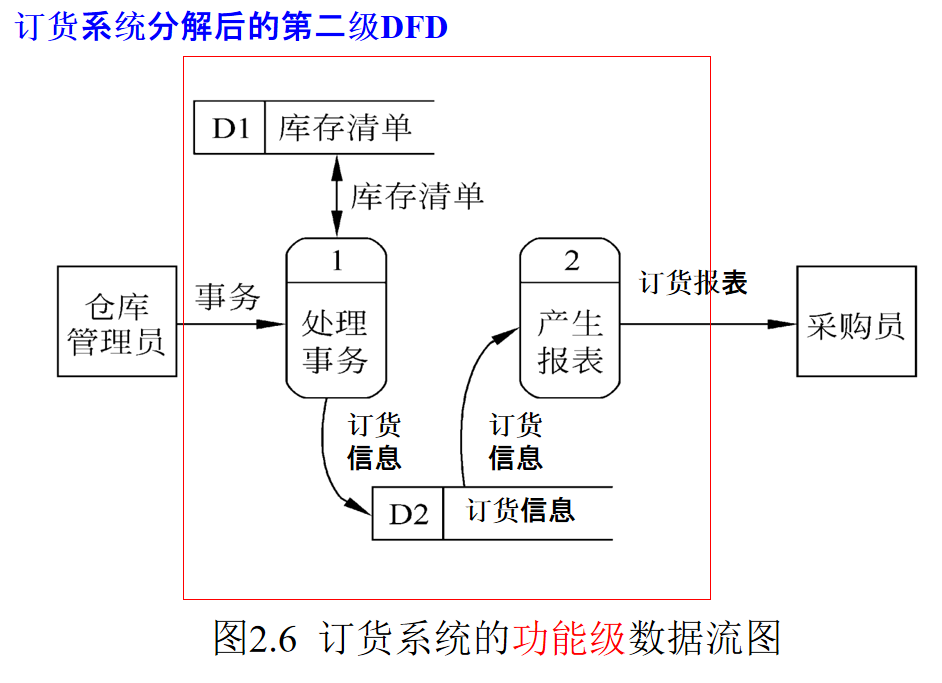
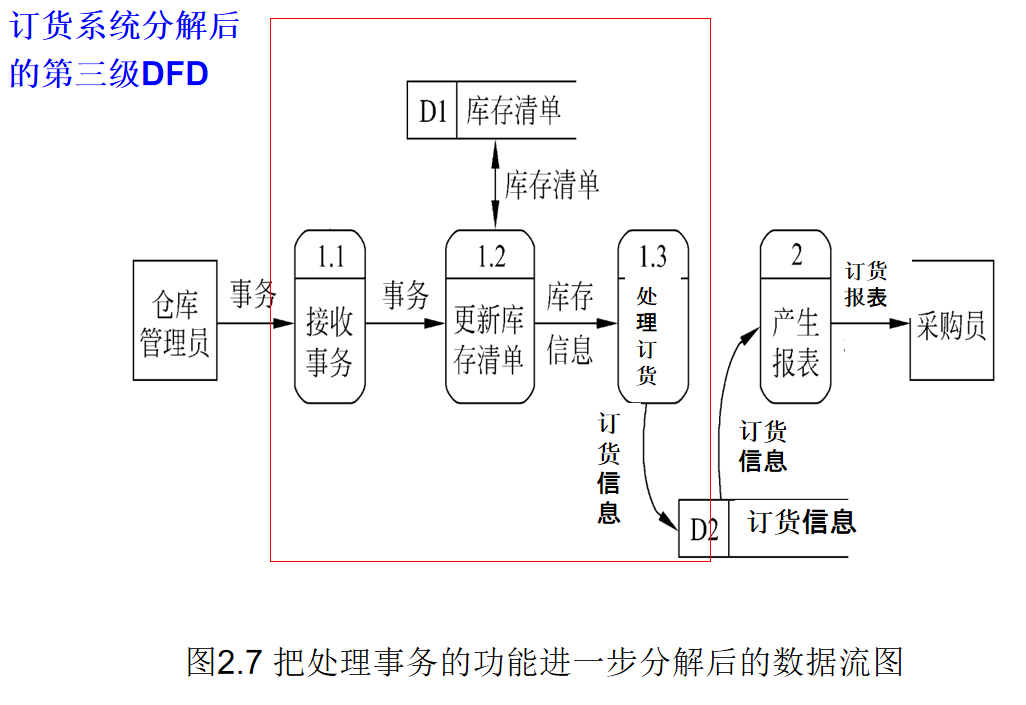
思考:DFD分解到什么时候结束?
每个主要功能都细化为一张数据流分图!
当进一步分解将涉及如何具体实现一个功能时就不应该再分解了!!
2.4命名
一、为数据流(或数据存储)命名
- 名字需代表整体内容,而非部分成分
- 避免使用 “数据”“信息”“输入” 等空洞、无具体含义的名字
- 命名遇困难,大概率是数据流图分解不当,可尝试重新分解
二、为处理命名
- 先给数据流命名,再为关联处理命名,贴合 “由表及里” 的人类思考习惯
- 名字要反映处理的整体功能,而非部分功能
- 优先用 “具体及物动词 + 具体宾语” 的形式,避免 “加工”“处理” 等空洞词汇
- 名字若仅含一个动词,需拆分则拆为两个处理更恰当
- 命名遇困难,多是分解不当,应重新分解
三、数据源点 / 终点命名
- 无需在开发目标系统时设计实现,属于系统外围环境
- 采用问题域中习惯的名字(如 “采购员”“仓库管理员”)
2.5数据流图用途
- 交流工具:描绘现有 / 目标系统逻辑,供相关人员审查确认;
- 易理解性:符号简洁(仅 4 种基本符号)、无物理实现细节,降低沟通门槛;
- 设计辅助:聚焦系统功能,支撑物理系统的分析与设计。
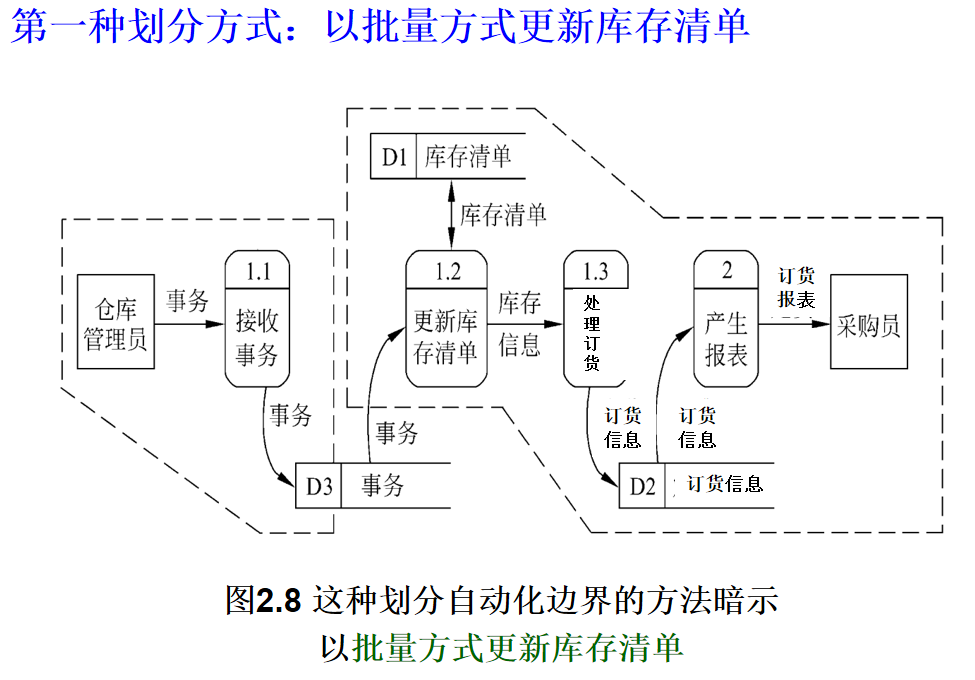
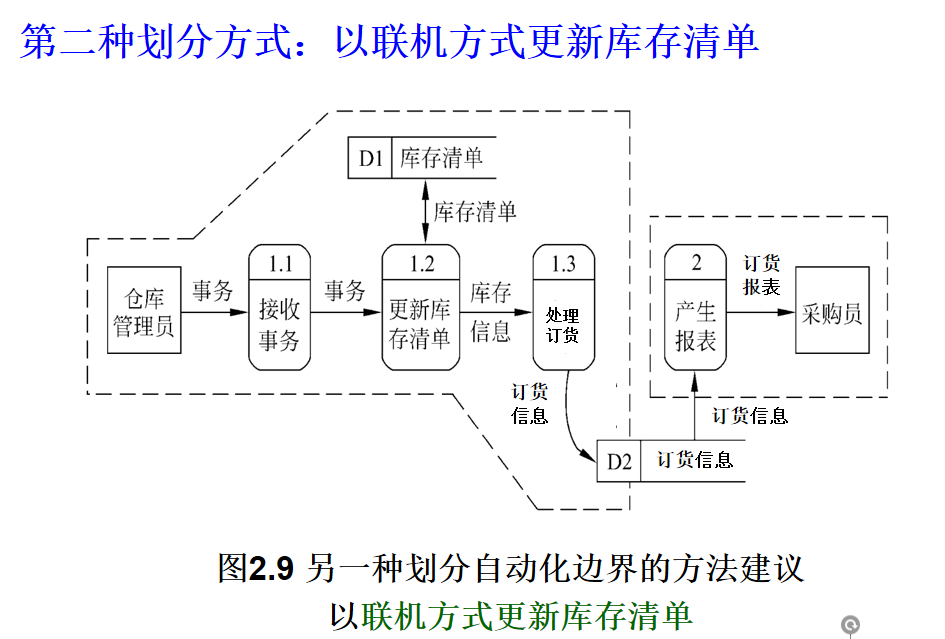
辅助物理系统设计时的自动化边界划分!
- 划分依据:以数据流图中各处理的定时要求为核心指南;
- 操作结果:可划分多组自动化边界,每组可能对应一种物理系统;
- 核心目的:根据系统逻辑模型考虑物理实现。

三、实体-联系图(ER)
ER------------Entity Relationship Diagram
- ER 图:数据模型的建模工具;
- 数据模型:面向用户、反映现实环境、与实现无关的问题导向模型;
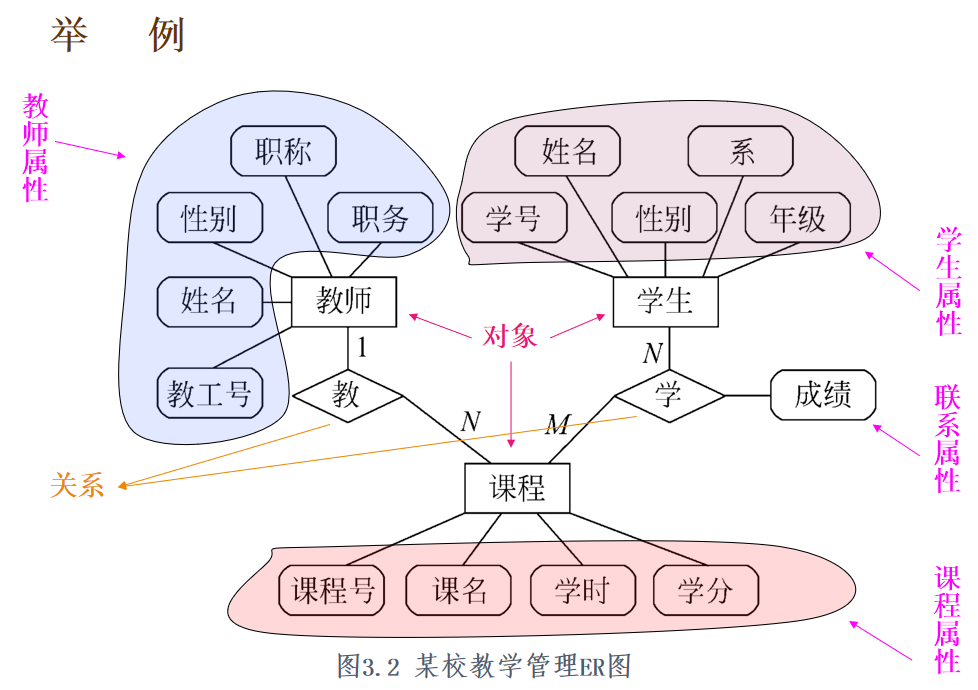
- 核心构成:数据对象(实体)、属性、实体间关系(三者相互关联)。
- 数据对象:是对软件需理解的复合信息的抽象,单个值的事物不属于数据对象。
- 属性:用于定义数据对象的性质。
- 联系:指数据对象间相互连接的方式,也称为关系。(一对一,一对多,多对多)
3.1实体-联系图的符号
- ER 图 3 种基本成分:实体、关系、属性;
- 符号对应:
- 实体:矩形框;
- 关系:连接实体的菱形框;
- 属性:椭圆形 / 圆角矩形(含实体属性、关系属性);
- 连接规则:实体 / 关系与对应属性用直线连接。
3.2举例
四、模块独立
- 核心定义:软件中每个模块的独立特性;
- 两大体现:仅负责具体子功能、与其他模块接口简单。
警告
模块独立程度的定性度量标准:耦合、内聚;
模块的独立性的优点
- 开发层面:便于开发出有效模块化的软件;
- 维护层面:独立模块更易测试与维护。
4.1耦合
定义:模块之间相互依赖、相互关联的紧密程度
耦合性高低的核心决定因素:模块接口复杂程度、模块调用方式、通过接口的数据

耦合程度强弱
按耦合程度从低到高排序
- 无耦合:模块完全独立,无需彼此即可工作,无任何连接;
- 数据耦合:仅通过参数交换简单数据,耦合性最低(常用且推荐);
- 控制耦合:交换信息含控制信息,中等耦合,增加程序复杂性;
- 特征耦合:传递整个数据结构,但被调用模块仅使用部分元素;
- 公共环境耦合:通过共享公共数据(如全局变量)关联,耦合度较高;
- 内容耦合:直接访问模块内部数据 / 跳转内部 / 代码重叠 / 多入口,耦合度最高(最不推荐)。
注意
尽量使用数据耦合, 少用控制耦合和特征耦合, 限制公共环境耦合的范围, 完全不用内容耦合。
4.2内聚
定义:模块内部各个元素之间彼此关联的紧密程度
注意
理想内聚的模块只做一件事情!
内聚与耦合的关系:模块内高内聚往往意味着模块间松耦合。
内聚的分类及特征
| 层级 | 类型 | 核心特征 |
|---|---|---|
| 低内聚 | 偶然内聚 | 模块任务关联松散,修改困难、出错概率高 |
| 逻辑内聚 | 任务在逻辑上属同类 / 相似,功能混杂,修改易影响全局 | |
| 时间内聚 | 任务需在同一时间执行,比逻辑内聚略优 | |
| 中内聚 | 过程内聚 | 处理元素相关且需按特定次序执行 |
| 通信内聚 | 模块元素使用同一输入数据 / 产生同一输出数据 | |
| 高内聚 | 顺序内聚 | 处理元素与同一功能密切相关,且顺序执行(前一元素输出为后一元素输入) |
| 功能内聚 | 模块元素属于整体,完成单一功能,是最高程度的内聚 |
内聚评分
功能内聚 10 分>顺序内聚 9 分>通信内聚 7 分>过程内聚 5 分>时间内聚 3 分>逻辑内聚 1 分>偶然内聚 0 分。
提示
- 核心结论:实践验证,高内聚比低耦合对模块独立性更重要;
- 设计侧重:软件设计应优先聚焦于提高模块的内聚性
五、程序复杂程度的定量度量—McCabe方法
基本原理:根据程序控制流的复杂程度定量度量程序的复杂程度(称为程序的环形复杂度)。
采用“流图”:仅描绘程序的控制流程,完全不表现对数据的具体操作及分支或循环的具体条件
5.1McCabe方法 基本步骤
- 将程序流程图或PDL等映射为流图。
- 基于流图计算环形复杂度,以定量度量程序的复杂程度。
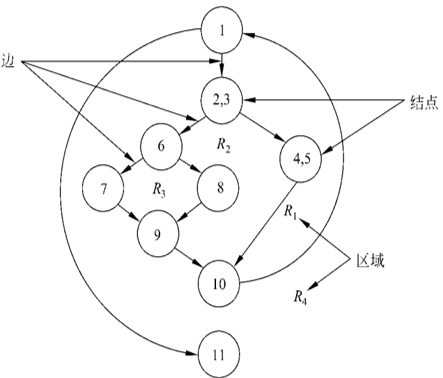
5.2流图
定义:仅仅描绘程序的控制流程
基本符号:
- 圆:表示结点,代表一条或多条语句。
- 箭头线:边
- 区域:由边和圆围成的面积。
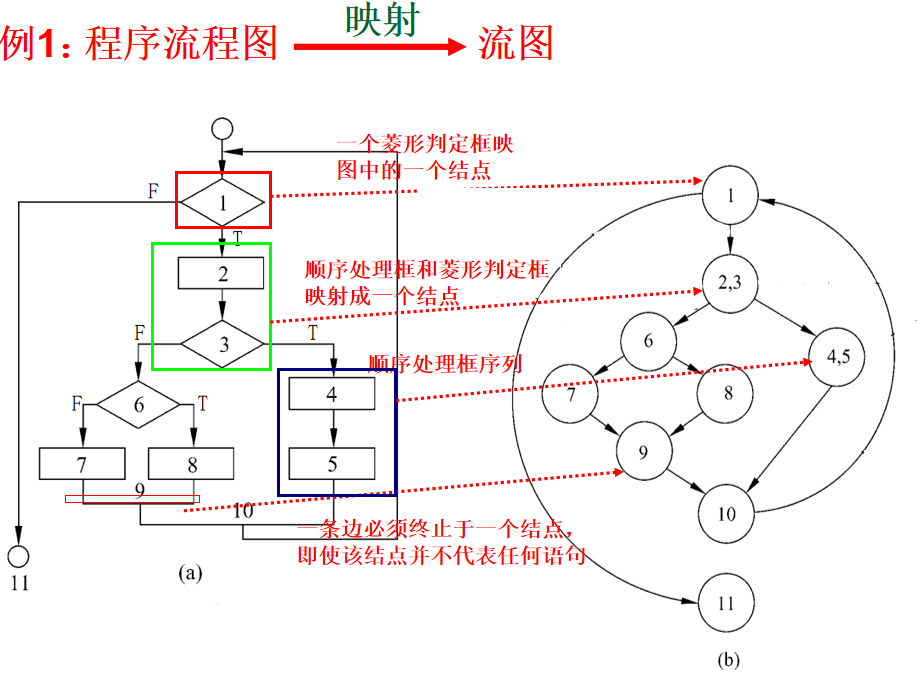
将程序流程图或PDL等映射成流程的基本原则:
- 合并原则:顺序处理框和菱形判定框、顺序处理框序列分别合并映射成流图中的一个结点。
- 分解原则:复合条件分解为若干个简单条件,每个简单条件映射成流图中一个结点。
- 其他情况下的框映射成流图中的一个结点。
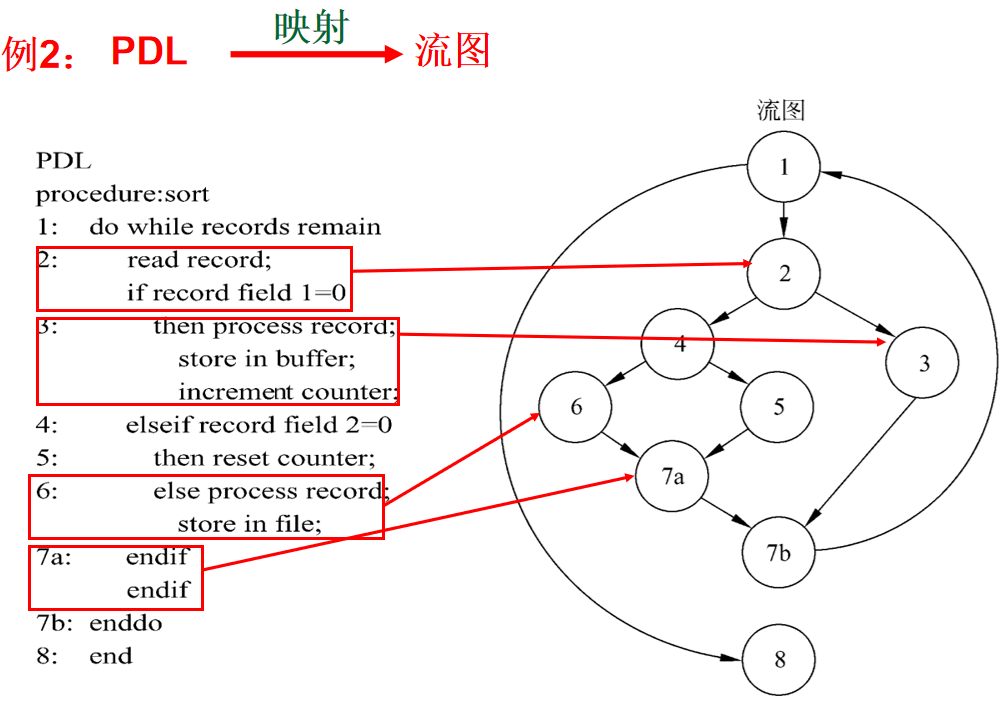
5.3计算环形复杂度的方法
McCabe方法基于流图中程序控制流的复杂程度定量度量程序的复杂程度,称为程序的环形复杂度。
(1)流图中的环形复杂度V(G)=区域数。
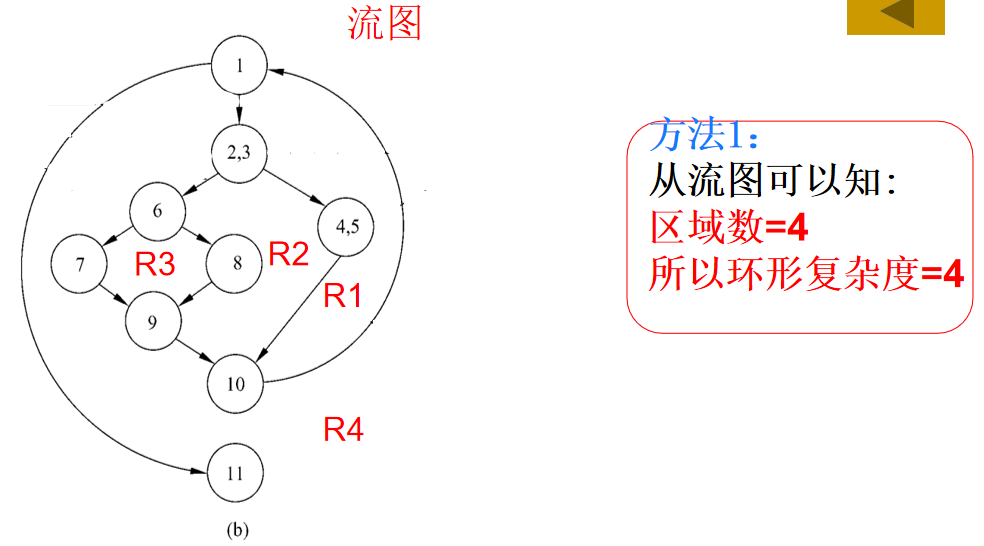
(2)流图G的环形复杂度V(G)=E-N+2,其中,E是流图中边的条数,N是结点数。
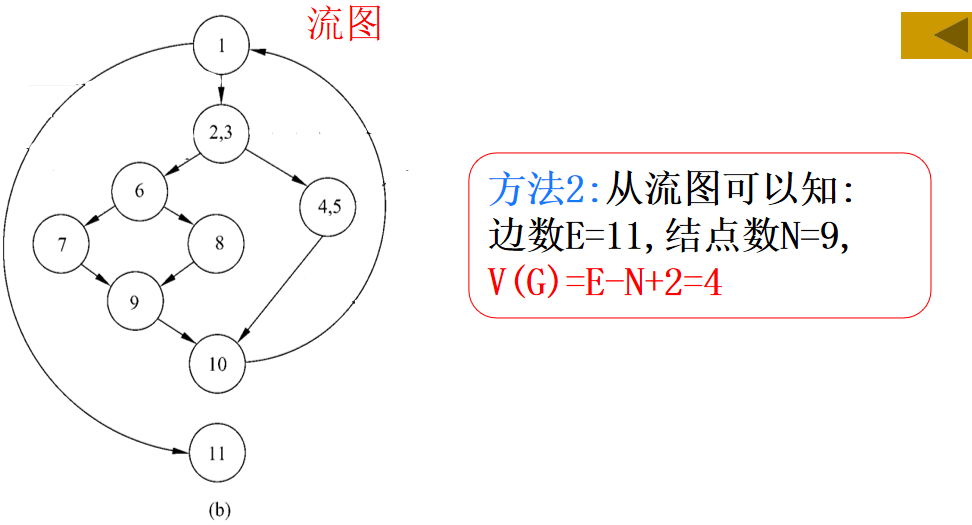
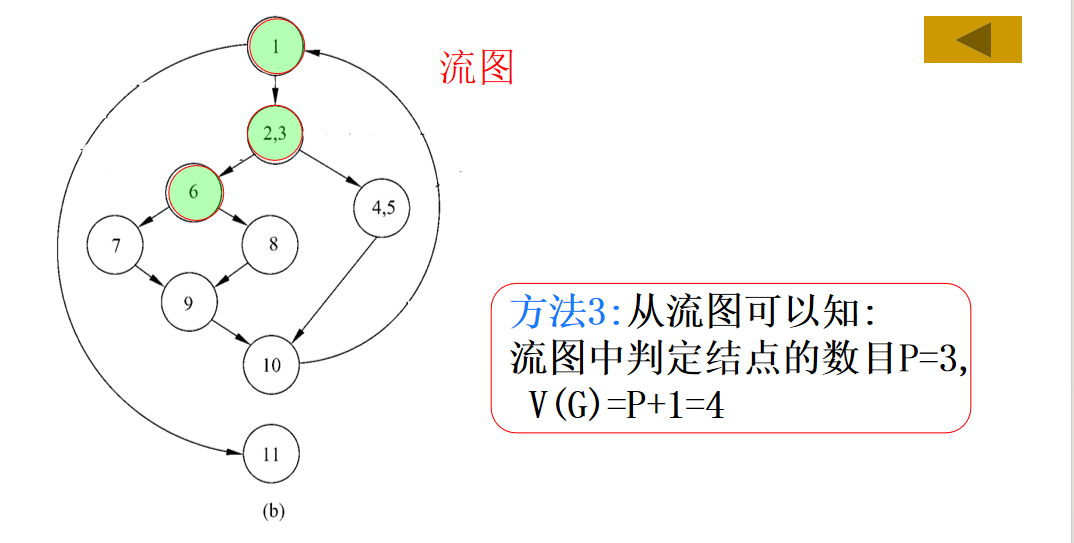
(3)流图G的环形复杂度V(G)=P+1,其中,P是流图中判定结点的数目。
5.4环形复杂度的用途
- 可以用于比较两个算法的优劣。对测试难度的一种定量度量。
- 作为模块规模的精确限度。环形复杂度高的程序往往是最困难、最容易出问题的程序。实践表明,模块规模以V(G)≤10为宜
六、编码风格
命名约定
缩进与空格
注释规范
语言特定规范
- 源程序文档化
- 数据说明
- 语句结构
- 输入/输出
- 效率
6.1源程序文档化
6.1.1、标识符的命名
- 贴合实际意义,见名知义;
- 简洁精炼,避免冗余;
- 缩写规则一致,必要时加注释;
- 变量单一用途。
6.1.2、程序的注释
程序注释是程序员与后续读者的重要通信手段,不可或缺;正规程序中注释行占比可达 1/3 至 1/2 甚至更多,注释分为序言性注释和功能性注释两类。
| 注释类型 | 位置 | 核心作用 | 关键词(抓重点) |
|---|---|---|---|
| 序言性 | 模块开头 | 整体说明(导览) | 标题、功能、算法、接口、开发信息 |
| 功能性 | 代码中间 | 局部解释(明细) | 代码段功能、意图、格式清晰 |
- 序言性:开头写 “说明书”(给模块做整体介绍,让人快速了解 “这是什么、能干嘛、怎么用”)
- 功能性:中间标 “操作注”(给代码块做具体说明,让人知道 “这段代码在干嘛、为啥这么写”)
6.1.3、视觉组织: 空格、空行和移行
合理运用空格可突出运算优先级、避免运算错误;程序段间用空行分隔;选择 / 循环语句内的程序段需阶梯式向右缩格,以清晰呈现程序逻辑结构。

6.2数据说明
- 说明次序标准化(常量→简单变量→数组→公用数据块),提升查阅、测试、调试和维护效率;
- 同一语句中多个变量说明按字母顺序排列;
- 复杂数据结构需用注解说明其方法和特点。
6.3语句构造
- 每个语句简单直接,不因追求效率导致程序过度复杂;
- 不刻意追求技巧性,避免程序编写过于紧凑。
语句构造需遵循以下规则,让语句简单明了:
- 一行仅写一个语句,不为节省空间合并;
- 简化复杂条件测试,剔除冗余逻辑;
- 减少 “非” 条件测试,避免读者理解绕弯;
- 避免大量循环嵌套和条件嵌套;
- 借助括号明确逻辑 / 算术表达式的运算次序,提升直观性。
6.4输入输出
- 验数据合法性;
- 格式简单、提示明确;
- 格式严则统一、报表清晰,数据加标志。
6.5效率
定义
程序效率 = 执行速度 + 内存占用
提高准则
- 基准:以需求为纲,不盲目堆人力
- 关键:靠良好设计,而 非硬凑代码
- 底线:不丢可读性,不做无谓优化
编码时提高程序运行效率的主要规则
- 简表达式:写代码前先简化算术 / 逻辑表达式,减少计算量;
- 移循环:嵌套循环 “内层语句外移”,避免重复执行;
- 避指针:尽量不用指针,减少内存寻址开销与风险;
- 不混类型:不同数据类型不混用,避免隐式转换损耗;
- 优先整数布尔算:运算优先用整数、布尔表达式,效率高于浮点 / 复杂表达式。
七、集成测试
集成测试:测试和组装软件的系统化技术。
渐增式测试:每次将一个待测试模块与已测试完成的模块结合测试,反复迭代直至所有模块全部测试完毕。
提示
单元测试需编写大量驱动程序和存根程序,为降低开销,可在渐增式测试过程中同步完成模块的详尽测试。
渐增式测试包括:自顶向下集成和自底向上集成
7.1自顶向下集成
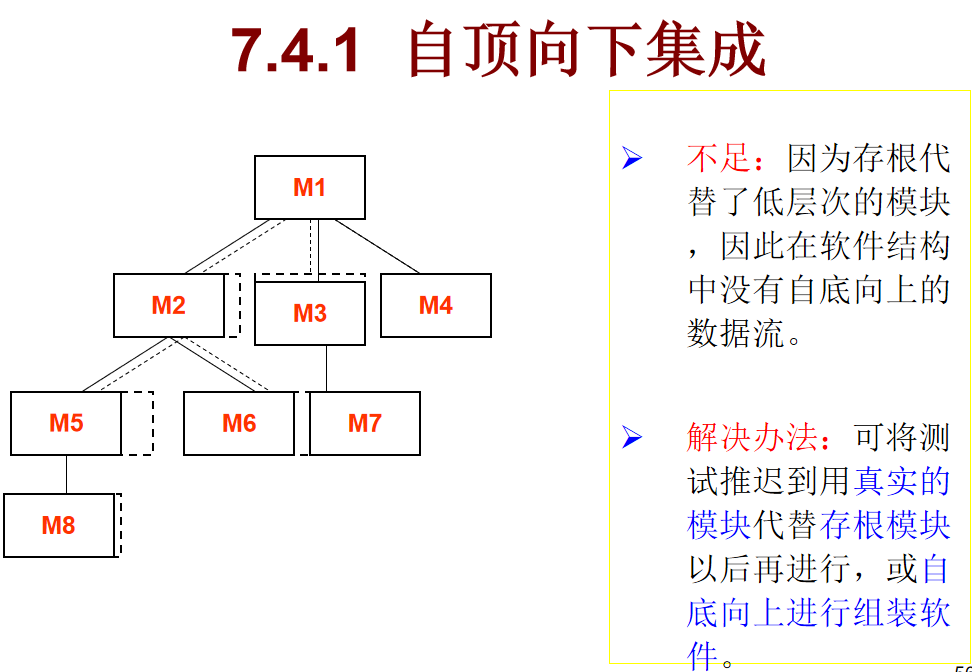
存根程序:模拟被依赖模块的 “最小必要行为”,让被测试模块能独立跑起来
首先,自顶向下集成的核心逻辑是:从软件结构的 顶层模块(比如图里的 M1) 开始,逐层把下层模块集成进来测试。过程中,还没开发好的低层次模块,会用 “存根模块”(图里虚线框的 M5、M6、M8 这类)临时替代,模拟它们的功能,先推进顶层模块的测试。
接着看它的不足:
因为用存根代替了真实的低层次模块,存根只是简易模拟(不是真实底层逻辑),所以软件结构里缺少 “自底向上的真实数据流”,会影响测试的真实性。
对应的解决办法:
要么等真实的低层模块开发完成、替换存根后,再做完整测试;要么结合 “自底向上集成” 的方法,先把底层模块组装好,再和顶层模块衔接测试。
7.2自底向上集成
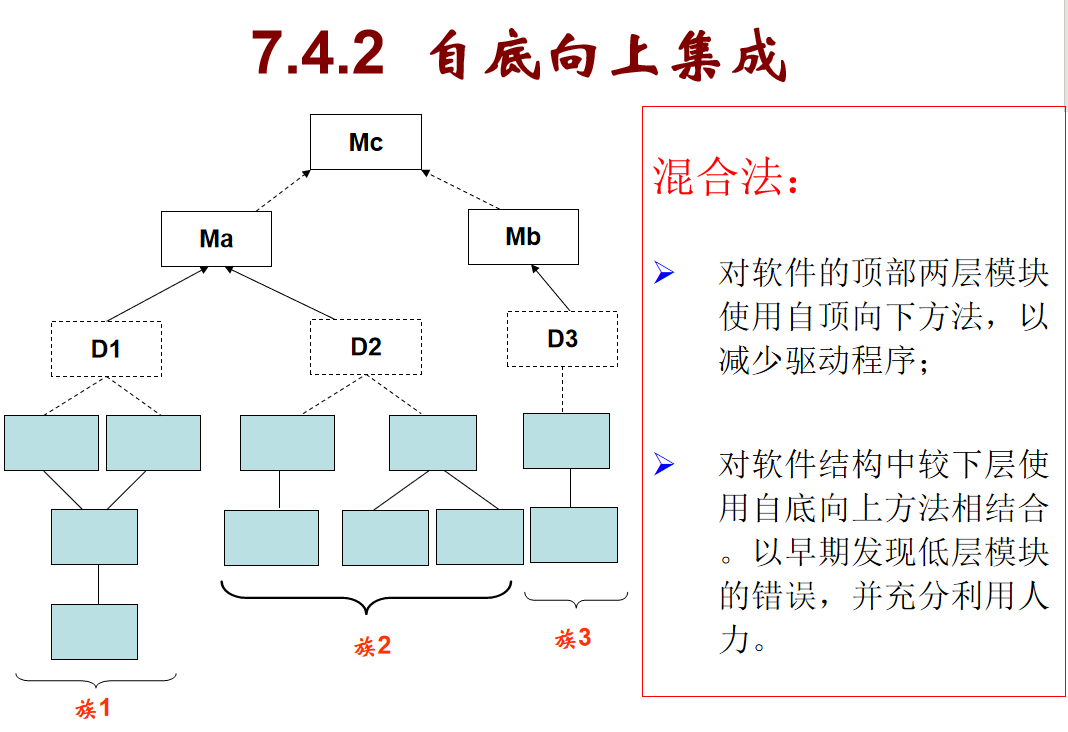
先看 “自底向上集成” 的核心逻辑:
它是从软件结构的最底层模块开始集成测试:
- 先把底层模块组合成 “族”(比如图里的 “族 1、族 2、族 3”),先测试这些底层模块的组合功能;
- 过程中,如果需要调用上层模块,会用 “驱动程序”(图里虚线框的 D1、D2、D3)临时替代,模拟上层的调用逻辑,先把底层功能验证好,再逐层向上和更高层模块集成。
再看 “混合法”(结合自顶向下 + 自底向上):
因为自顶向下、自底向上各有优缺点,混合法是为了互补:
- 对软件顶部两层模块用 “自顶向下” 方法:能减少 “驱动程序” 的编写(自底向上需要写驱动,自顶向下用存根,顶部用前者更省成本);
- 对软件较下层模块用 “自底向上” 方法:可以更早发现底层模块的错误,还能按 “族” 拆分测试任务,充分利用人力并行测试。
警告
- 存根程序:替「被测试模块依赖的模块」干活(被动响应);
- 驱动程序:主动调用「被测试模块」,给它喂测试数据、捕获结果(主动发起)。
Alpha和Beta测试
- Alpha 测试:用户在开发者场所、受控环境下进行,开发者指导并记录问题。
- Beta 测试:最终用户在真实、非受控环境中使用,自行记录并反馈问题。
八、白盒测试技术
白盒测试(结构测试) 的核心是:基于程序内部代码逻辑、结构和路径设计测试用例,验证代码执行流程和逻辑是否符合预期。
测试用例:为测试设计的数据。主要由测试输入数据和预期的输出结果两部分组成。
8.1逻辑覆盖
以程序的逻辑结构为基础设计测试用例的技术。
按测试数据覆盖程序逻辑的程度划分成
- 语句覆盖
- 判定覆盖
- 条件覆盖
- 判定/条件覆盖
- 条件组合覆盖
- 路径覆盖
8.1.1语句覆盖
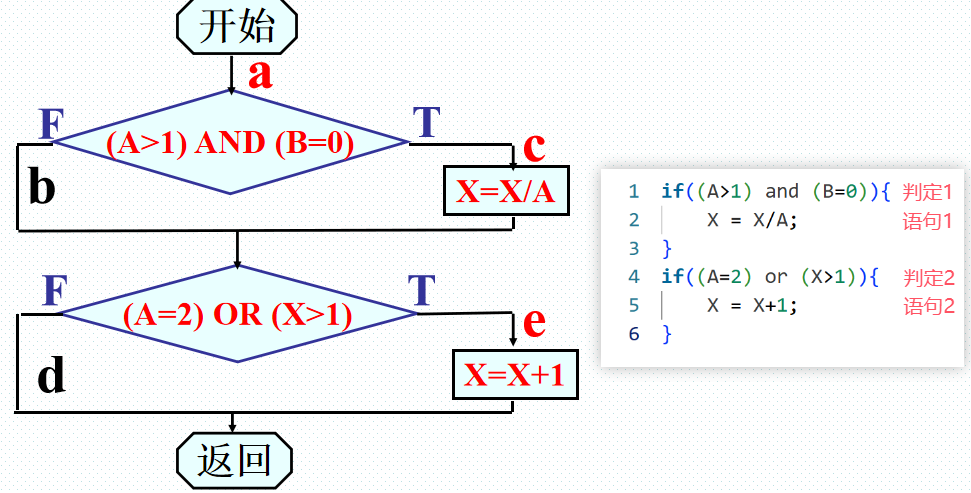
定义:每条语句至少执行一次
测试目标:覆盖语句 1、语句 2
测试用例:
| 输入数据A B X | 预期输出A B X |
|---|---|
| 2 0 4 | 2 0 3 |
面临的问题:
能比较全面地检验每个语句,但是无法检测逻辑运算问题(如:AND 写成 OR, X>1 写成 X <1 ),因此,语句覆盖是最弱的逻辑覆盖。
8.1.2判定覆盖
定义:每个判定的真分支和假分支至少执行一次
测试目标:判定1和判定2的真假分支
测试用例示例1:
| 输入数据A B X | 预期输出A B X | 覆盖分支 |
|---|---|---|
| 2 0 4 真 | 2 0 3 真 | ce |
| 1 0 1 假 | 1 0 1 假 | bd |
测试用例示例2
| 输入数据A B X | 预期输出A B X | 覆盖分支 |
|---|---|---|
| 3 0 3 真 | 3 0 1 假 | cd |
| 2 1 1 假 | 2 1 2 真 | be |
面临问题:
该测试用例仍无法检测内部条件的错误(如将X>1误写成X<1)
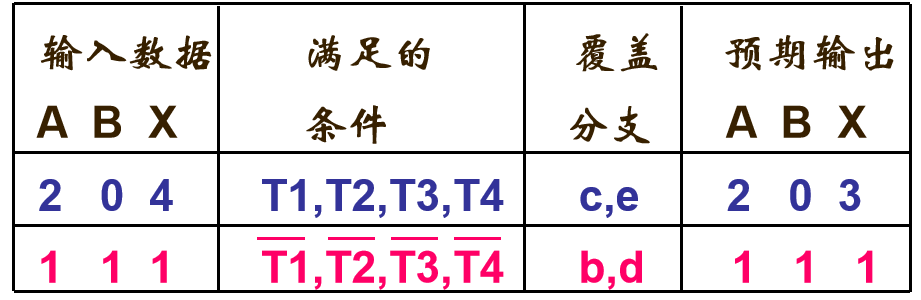
8.1.3条件覆盖
定义:每个条件的真假至少取一次
测试目标:A>1的真/假。B=0的真/假,A=2的真/假。X>1的真/假

测试用例:
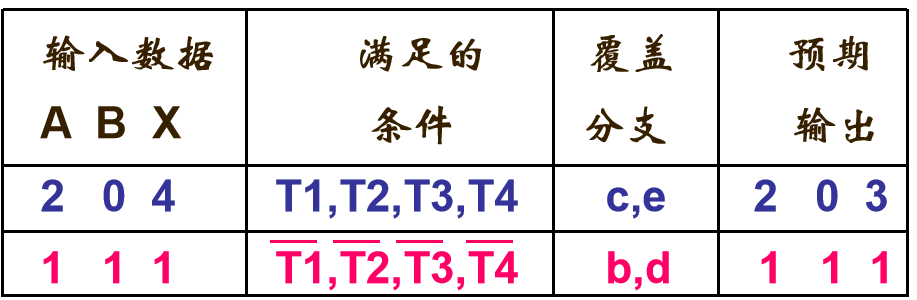
8.1.4判定/条件覆盖
定义:所有判定的真假分支都覆盖 + 所有条件的真假取值都覆盖
测试用例:
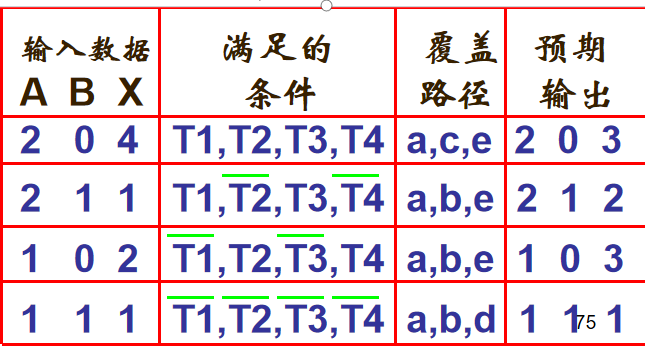
8.1.5条件组合覆盖
定义:每个判定中所有条件的可能组合至少出现一次
测试用例:
8.1.6路径覆盖
定义:覆盖程序的所有可能执行路径
测试用例:
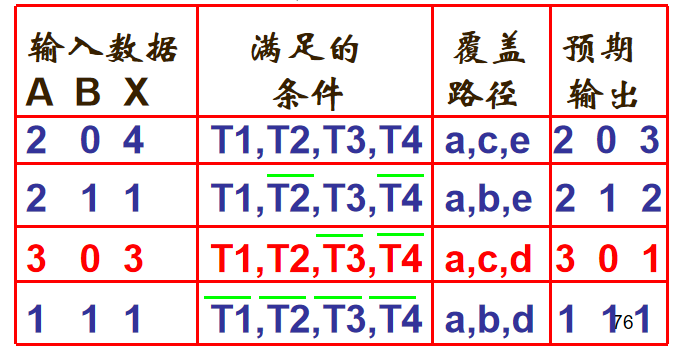
注意
即使做到了路径测试,也不能保证程序的正确性。测试的目的不是证明程序是正确的,而是尽力找出尽可能多的错误。
九、黑盒测试技术
- 核心:侧重测试软件功能;
- 关系:与白盒测试互补,不可相互取代;
- 优势:能发现白盒测试难察觉的特定类型错误。
黑盒测试重点排查 5 类错误:
- 功能问题(不正确 / 遗漏);
- 界面错误;
- 数据 / 数据库访问错误;
- 性能错误;
- 初始化 / 终止错误。
设计黑盒测试方案时,应该考虑下述问题:
- 测试阶段:白盒测试(早期),黑盒测试(后期);
- 黑盒测试方案设计 6 大核心问题:
- 功能有效性如何验证?
- 哪些输入构成优质测试用例?
- 系统对特定输入是否敏感?
- 数据类边界如何划分?
- 系统可承受的数据率 / 量是多少?
- 数据特定组合对系统运行有何影响?
9.1等价类划分法(等价分配)
- 背景:穷尽黑盒测试不现实,需选取代表性输入数据;
- 核心思想:将输入域划分为若干等价类(同类数据效果一致);
- 目标:以少量用例覆盖更多错误,降低测试代价。
警告
- 划分范围:覆盖所有有效 + 无效输入数据;
- 划分结果:拆分为若干等价子集(别名:等价类别 / 区间);
- 核心特性:子集内任一典型值的测试效果,与该子集所有其他值完全一致。
9.1.1如何划分等价类
研究程序的功能说明,确定
- 有效等价类(合理等价类)
- 无效等价类(不合理等价类)
9.1.2划分等价类的主要规则
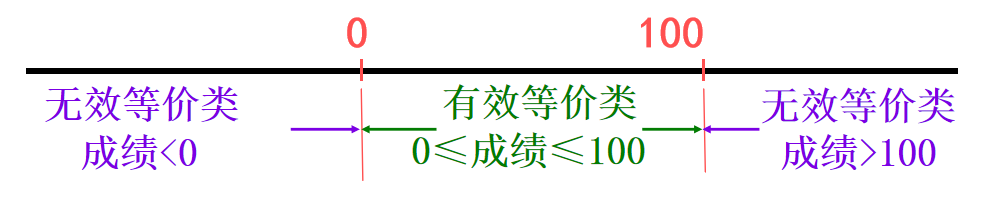
(1)如果输入条件规定了取值范围,可定义一个有 效等价类和两个无效等价类。
例 输入值是学生成绩,范围是0~100
(2)如果输入条件规定了输入数据的个数,可定义一个有效等价类和两个无效等价类。
例 输入关键词个数只允许是3~5个

(3)如规定了输入数据的一组值,且程序对不同输 入值做不同处理,则每个允许的输入值是一个 有效等价类,并有一个无效等价类(所有不允 许的输入值的集合)。
例:输入条件说明学历可为:专科、本科、硕士、博士四 种之一,则分别取这四个值作为四个有效等价类, 另外把四种学历之外的任何学历作为无效等价类。
9.1.3用等价类划分法设计测试用例步骤:
步骤1:有效等价类覆盖:单个用例尽可能多覆盖未覆盖的有效类,重复至所有有效类全覆盖;
步骤2:无效等价类覆盖:单个用例仅覆盖一个未覆盖的无效类,重复至所有无效类全覆盖。
9.1.4例子
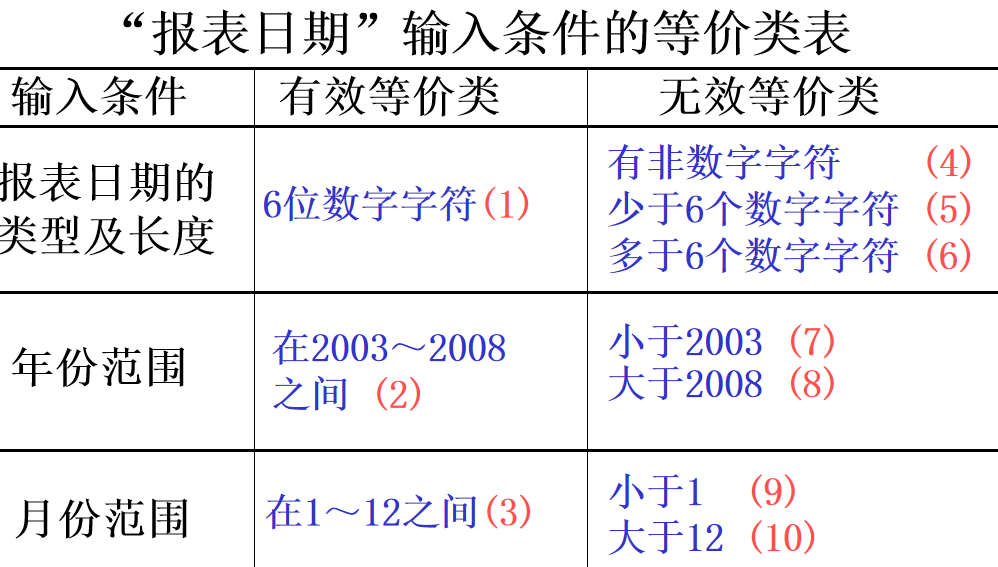
例:某报表处理系统要求用户输入处理报表 的日期,日期限制在2003年1月至2008年 12月,即系统只能对该段期间内的报表 进行处理,如日期不在此范围内,则显 示输入错误信息。 系统日期规定由年、月的6位数字字符组 成,前四位代表年,后两位代表月。
如何用等价类划分法设计测试用例, 来测试程序的日期检查功能?
第一步:等价类划分
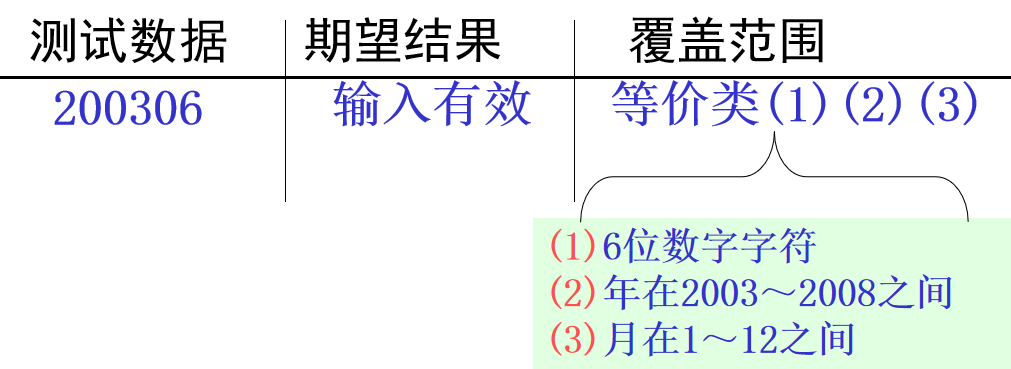
第二步:为有效等价类设计测试用例
对表中编号为1,2,3的3个有效等价类用一个测试
第三步:为每一个无效等价类设至少设计一个测试用例
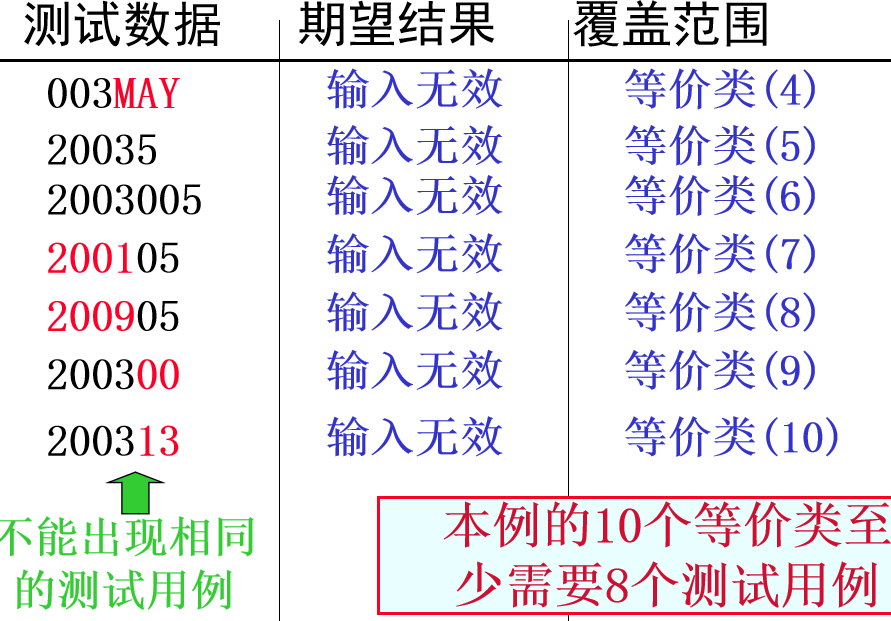
例子2
例:对招干考试系统“输入学生成绩”子模块 设计测试录入准考证号的测试用例
准考证号数据格式定义:共6位数字组成,其中第一位为专业代号:1-行政专业,2-法律专业,3-财经专业后5位为考生顺序号,编码范围为:
行政专业准考证号码为:110001~111215
法律专业准考证号码为:210001~212006
财经专业准考证号码为:310001~314015

9.2边界值分析法
测试临近边界的合法数据,以及刚超过边界的非法数据。
越界测试: 对于最大值,通常简单地加1或很小的数。对于最小值,通常减1或很小的数。
边界值分析示例
| 输入 | 预期输出 | |
|---|---|---|
| (1)使输出刚好等于最小的负整数 | -32768 | -32768 |
| (2)使输出刚好等于最大的正整数 | 32767 | 32767 |
| (3)使输出刚好小于最小的负整数 | -32769 | 错误——无效输入 |
| (4)使输出刚好大于最大的正整数 | 32768 | 错误——无效输入 |
9.3错误推测法
1. 核心思想 错误推测法是一种高度依赖测试人员经验、直觉和创造力的测试用例设计技术。它并没有固定的公式或步骤,而是基于测试人员对软件系统、类似项目、常见编程缺陷以及过往测试经验的理解,主动“猜测”程序在哪些地方可能隐藏着错误,并据此设计针对性的测试用例。
十、面向对象建模
- 核心要求:需构建 3 类模型,覆盖数据、控制、功能维度;
- 具体模型:
- 【对象模型】:描述系统数据结构,是最基本、最核心的模型;
- 【动态模型】:描述系统控制结构;
- 【功能模型】:描述系统功能。
10.1对象模型
用统一建模语言UML表达的对象模型由**类图(类和类间关系)**构成。
10.1.1类图的基本符号
[可见性] 属性名: 类型名=初值
——属性的[可见性]: 公有的(public) (+) 、私有的(private) (-)、 保护的(protected) (#)
——类型名表示该属性的数据类型,它可以是基本数据类型,也可以是用户自定义的类型。
——{性质串}明确地列出该属性所有可能的取值,也可以说明属性的其他性质。
e.g. “+婚否:布尔=假{真,假}”
10.2功能模型
- 工具:UML 用例图(面向对象方法下,需求分析 + 功能建模的核心工具);
- 用例模型本质:从用户视角,描述外部行为者(actor)所理解的系统功能。
10.2.1用例图
用例建模的元素:
- 系统:建模的目标对象;
- 行为者(Actor):系统外,通过边界与系统交互的人 / 事物(角色);
- 关系:用户与用例的通信联系、用例之间的关联;
- 用例(Use Case):表示系统提供的服务,主要刻画系统如何被行为者使用。
10.2.2用例建模步骤(4步)
1) 识别参与者
2)识别用例
3)识别关系
4)建模
十一、面向对象分析
11.1面向对象分析的基本过程
面向对象分析
(1) 其关键是识别出问题域内的类与对象,并分析它们相互间的关系,最终建立起3种模型。
(2)对象模型最基本、最重要、最核心
3个子模型:对所解决问题的描述角度进行划分:

5个层次:

面向对象分析的过程
- 寻找类与对象
- 识别结构
- 定义属性
- 建立动态模型
- 定义服务
面向对象分析不可能严格地按预定顺序进行,大型、复杂系统的模型需要反复构造多遍才能建成。先构造模型的子集,再到完全地理解整个问题,最终建立整个模型。
Gantt图有什么缺点
复杂项目可读性差
缺乏灵活性
不体现任务优先级
不适合敏捷 / 迭代型项目
维护成本高
直观简明和容易掌握、容易绘制的优点软件配置管理的过程
标识、版本控制、变化控制、配置审计和报告
三个简答题:每题10分
三个分析题:每题10分
两个设计题:每题20分
用例图和类图
六种白盒测试